
我們昨天認識 Ray 這個神奇套件如果載入跟處理資料,今天來看看模型訓練的部分。
根據官網所述,要了解 Ray Train 的運作方式,要先了解他的四個概念:
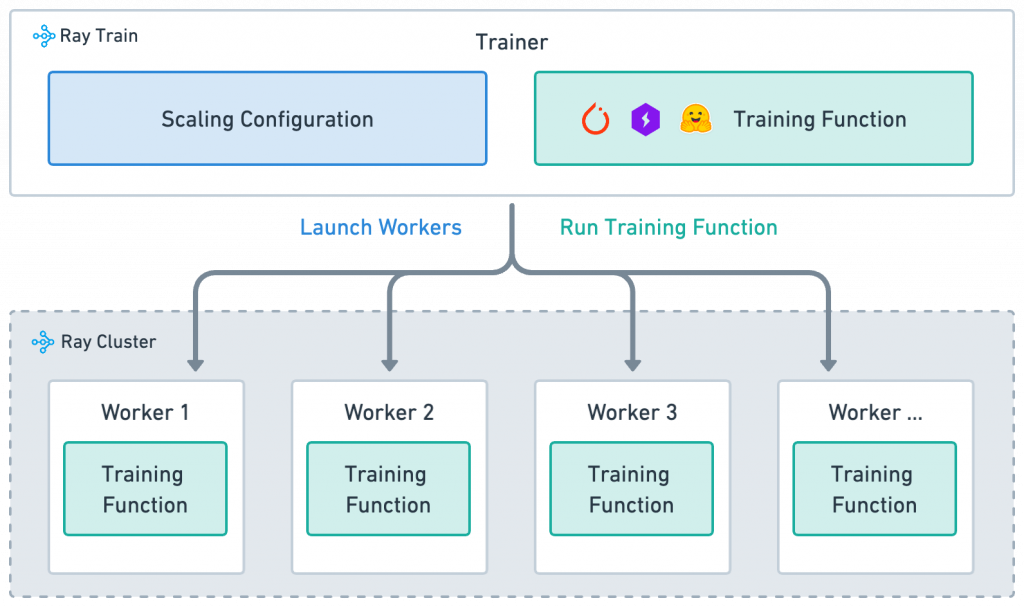
圖片來源:[1]
def train_func():
# do some training
Worker:執行 training function 的小工人,worker 的數量決定有幾個平行的訓練作業,可在 ScalingConfig 中設定。
Scaling configuration:定義訓練作業規模的設定,用 num_workers 決定 workers 數量,用 use_gpu 決定是否用 GPU 訓練。
from ray.train import ScalingConfig
# Multiple workers, each with a GPU
scaling_config = ScalingConfig(num_workers=4, use_gpu=True)
fit() 會執行訓練作業。from ray.train.torch import TorchTrainer
trainer = TorchTrainer(train_func, scaling_config=scaling_config)
trainer.fit()
認識到四個重要概念後,接下來我們來訓練模型吧!
官網有列出只使用 Pytorch 跟 Pytorch + Ray Train 的前後差異,我們這邊就不特別討論。我們會發現使用 Ray Train 幾乎沒有改到原本的程式碼,只是多加了幾行 Ray 的使用,顯示他真的可以非常輕鬆地整合進原本的程式碼中。
將上述的四個概念結合的程式碼後,如下所示,這就是基本使用 Ray 的架構
from ray.train.torch import TorchTrainer
from ray.train import ScalingConfig
def train_func():
# model training function
scaling_config = ScalingConfig(num_workers=2, use_gpu=True)
trainer = TorchTrainer(train_func, scaling_config=scaling_config)
result = trainer.fit()
我們依照模型的訓練步驟來逐步講解使用方式,以下都以 Pytorch 為例,想看 Tensorflow 或 HuggingFace 的朋友,請直接去參考官網。
上面示範的 train_func 是沒有任何 input argument 的,不過如果想要傳入一些 config 進來,也可以包成 dictionary 的形式,再利用 Trainer 傳入。
def train_func(config):
lr = config["lr"]
num_epochs = config["num_epochs"]
config = {"lr": 1e-4, "num_epochs": 10}
trainer = ray.train.torch.TorchTrainer(train_func, train_loop_config=config, ...)
❗️❗️❗️ 資料集跟模型的載入都要在
train_func中,但是,官方不建議將他們直接傳入train_func,可以利用以下做法:
def load_dataset():
# Return a large in-memory dataset
...
def load_model():
# Return a large in-memory model instance
...
-config = {"data": load_dataset(), "model": load_model()} # ❗️❗️❗️ 不要這樣寫
def train_func(config):
- data = config["data"] # ❗️❗️❗️ 不要這樣寫
- model = config["model"] # ❗️❗️❗️ 不要這樣寫
+ data = load_dataset() # ✅ 建議方式
+ model = load_model() # ✅ 建議方式
...
trainer = ray.train.torch.TorchTrainer(train_func, train_loop_config=config, ...)
以下分為兩種方式:
(1) 資料集還是 Pytorch 的 DataLoader 形式,需要先轉成 Ray Train 的格式
def train_func():
# 準備資料集
dataset = ...
# Pytorch 的 DataLoader
data_loader = DataLoader(dataset, batch_size=worker_batch_size, shuffle=True)
# 轉成 Ray Train
data_loader = ray.train.torch.prepare_data_loader(data_loader)
for epoch in range(10):
if ray.train.get_context().get_world_size() > 1:
data_loader.sampler.set_epoch(epoch)
for X, y in data_loader:
- X = X.to_device(device) # ❗️不需要,Ray Train 會自動處理
- y = y.to_device(device) # ❗️不需要,Ray Train 會自動處理
...
(2) 直接用 Ray Data 載入資料集,不需要再特別處理
如果想要看更詳細的說明,請參考 [3]。
# [Step 1] 直接用 Ray Data 載入資料集
train_dataset = ray.data.from_items([{"x": [x], "y": [2 * x]} for x in range(200)])
def train_func():
...
# [3] 可以直接從 training worker 獲取 dataset
train_data_shard = train.get_dataset_shard("train")
train_dataloader = train_data_shard.iter_torch_batches(
batch_size=batch_size, dtypes=torch.float32
)
for epoch_idx in range(10):
for batch in train_dataloader:
inputs, labels = batch["x"], batch["y"]
trainer = TorchTrainer(
train_func,
datasets={"train": train_dataset}, # [Step 2] 傳入 Ray Dataset
scaling_config=ScalingConfig(num_workers=2, use_gpu=use_gpu)
)
result = trainer.fit()
可以發現,無論是否直接使用 Ray Data 載入資料集,其實都沒有改變太多原本的程式碼。
def train_func():
# 準備模型
model = resnet18(num_classes=2) # 原本的模型
model = ray.train.torch.prepare_model(model) # 轉成 Ray Train
- model = model.to(device_id or "cpu") # ❗️不需要,Ray Train 會自動處理
def train_func():
...
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
torch.save(
model.state_dict(), os.path.join(temp_checkpoint_dir, "model.pt")
)
metrics = {"loss": loss.item()} # 想要紀錄的 metrics
# 建立一個 Ray Train checkpoint
checkpoint = ray.train.Checkpoint.from_directory(temp_checkpoint_dir)
ray.train.report(metrics=metrics, checkpoint=checkpoint)
...
run_config = RunConfig(storage_path="/some/local/path", name="unique_run_name")
trainer = TorchTrainer(
train_func, scaling_config=scaling_config, run_config=run_config
)
result = trainer.fit()
以上就是 Ray Train 的簡單介紹,他可以蠻無痛地整合進去已經寫好的程式碼,所以推薦大家都玩玩看!
最後,我們在訓練模型時一定需要嘗試各種 hyperparameters 的組合,我之前都是用 Optuna,不過 Ray Tune 有提供非常簡潔的方式,如下所示:
from ray import train, tune
def train_func():
...
def objective(config): # 定義 objective function
...
train_func(model, train_loader) # 一樣使用 training function
acc = test_func(model, test_loader) # 測試在 testing dataset
return {"acc": acc}
search_space = { # 定義要搜尋的 hyperparameters
"lr": tune.grid_search([0.001, 0.01, 0.1]),
"n_layers": tune.choice([1, 2, 3]),
}
# 開始訓練
tuner = tune.Tuner(objective, param_space=search_space)
results = tuner.fit()
print(results.get_best_result(metric="score", mode="min").config) # 獲得結果
就這樣寫完了!是不是很驚人,[4] 有顯示 Optuna 跟 Ray Tune 的比較,後者真的是簡潔很多,而且一樣可以借力於 Ray 的分散式計算框架。
這兩天大致介紹 Ray 的基本使用方式,不過一些細節和進階用法,在官網都寫的非常清楚,推薦大家都去玩玩看哦!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference
[1] https://docs.ray.io/en/latest/train/overview.html
[2] https://docs.ray.io/en/latest/train/getting-started-pytorch.html
[3] https://docs.ray.io/en/latest/train/user-guides/data-loading-preprocessing.html#data-ingest-torch
[4] https://docs.ray.io/en/latest/tune/index.html

 iThome鐵人賽
iThome鐵人賽